









Si vous êtes déjà informés sur ce qu’est un serveur sous Linux et comment il peut être configuré pour devenir un serveur web, vous pouvez passer directement aux commandes.
Pourquoi un serveur ?
Nous développons des sites web pour nos clients, et ces sites sont hébergés sur un serveur. C’est de cette façon qu’ils sont accessibles, via Internet, à tout le monde.
Ces serveurs sont comme des ordinateurs, seulement ils ne sont composés que d’une unité centrale. Pas de clavier ni d’écran car sans interface graphique, tout se fait en lignes de commandes depuis une autre machine. Ils sont allumés et reliés à Internet en permanence. De ce fait, le serveur doit être installé, maintenu, sauvegardé, sécurisé… Un métier est dédié à ce travail : il s’agit de l’administrateur système, couramment appelé SysAdmin.
Chaque serveur est d’abord composé d’un système d’exploitation. Plusieurs familles existent, notamment Unix (Linux, MacOS) et Windows. Oui, MacOS a beaucoup de similitudes avec Linux car ils découlent de la même famille ! Cependant, l’un est gratuit et open source, tandis que l’autre est exploité par Apple pour ses appareils uniquement. C’est une des raisons pour lesquelles les appareils Apple sont adaptés pour le développement web.
Il se trouve que la majorité des serveurs tournent sous Linux. Pourquoi ? C’est l’option privilégiée en raison de sa gratuité et de la grande communauté qui le fait grandir en termes de ressources et d’accompagnement. À noter que l’appellation exacte du système d’exploitation est GNU/Linux, car la version utilisée aujourd’hui est un mélange de ces deux systèmes d’exploitation.
Au sein d’une même famille de système d’exploitation, il y a diverses distributions. La distribution d’un serveur est un autre système d’exploitation : Linux, GNU… Et ainsi de suite, par exemple pour Linux il en existe encore de nombreuses : d’un côté les distributions à destination d’une utilisation individuelle, tels que Linux Mint, Red Hat, ou des distributions orientées serveur : Debian, Ubuntu CentOS.
Utilisation serveur de Linux
Vous l’aurez compris, les serveurs utilisent donc Linux et notamment les distributions Debian ou Ubuntu en majorité.
En tant que développeurs web, nous avons souvent accès à ces serveurs, afin de rendre nos sites web accessibles à tous puis de les mettre à jour. Pour cela, nous utilisons plusieurs protocoles. Vous connaissez le protocole HTTPS qui vous permet de naviguer sur Internet. Savez-vous qu’il en existe beaucoup d’autres ?
- FTP et SFTP : utilisé pour le transfert de fichier entre un ordinateur et un serveur.
- SSH : permet d’accéder au serveur à distance, en toute sécurité
- SMTP : permet l’envoi d’e-mails
Lorsqu’un site web est en cours de développement, il n’existe encore qu’en « local ». Cela signifie qu’il n’est accessible que sur l’ordinateur d’où il est développé, via une URL telle que localhost:3000. Il n’est pas disponible à tous, mais une fois qu’il sera prêt, il faudra le déployer sur un serveur. D’abord en transférant les sources (fichiers, dossiers, images…), puis en effectuant tout un tas de commandes pour le faire marcher (vider le cache, démarrer des services).
Les différents serveurs
Il en existe beaucoup mais deux en particulier vont permettre de rendre un site accessible « en ligne ». Sans rentrer dans les détails, les serveurs e-mails accompagnent aussi souvent la création d’un site web qui se place sur le même nom de domaine.
Le serveur DNS
Il est celui qui associe une adresse IP à un nom de site, bien plus facile à lire et à retenir pour un humain qu’une suite de nombre. Cette donnée est à renseigner dans la zone DNS du nom de domaine, éditable depuis le registrar où il a été acheté. À noter qu’une zone DNS doit se propager à travers les serveurs du monde entier, ce qui peut prendre plus ou moins de temps. Un bon réflexe est d’informer que cette donnée va changer en baissant le TTL (Time To Live) quelques jours à l’avance.
Le serveur web
Il a pour fonction de servir des pages HTML, qui est le langage interprété par les navigateurs. Parfois il s’agit de pages statiques sur lesquelles il n’effectue aucun calcul, la plupart du temps il s’agit de pages dynamiques. Dans ce cas, le serveur reçoit du PHP, effectue des calculs selon la requête et le contexte donné, et renvoie du HTML. La page affichée peut donc être complètement différente selon les paramètres.
Il existe plusieurs logiciels de serveur web, mais il y en a deux en particulier qui se partagent 80% du marché : Apache et Nginx. Leur configuration est différente ainsi que leur façon de faire, mais ils sont tous deux open-source et ont leurs avantages. Nginx est connu notamment pour être plus performant en cas de trafic important, mais Apache est puissant dans un contexte d’environnement mutualisé grâce à sa configuration partagée entre les dossiers.
Au niveau de la configuration, le serveur web centralise tout ce qui est :
- Redirection, réécriture d’URL, certificat SSL pour connexion sécurisée en HTTPS
- Base de données : via MySQL, MariaDB, PostgreSQL et beaucoup d’autres
- Langages de programmation : PHP, NodeJS
Des concepts à savoir
Les permissions utilisateurs sont souvent source de problème, il faut savoir trouver le juste milieu entre des blocages de sécurité et des accès nécessaires pour le fonctionnement du site.
Lors de l’affichage du contenu d’un dossier avec ls, la première ligne affiche les permissions de ce fichier/dossier.
Prenons par exemple le dossier d’un site très simple, composé d’un seul fichier index.html et d’un dossier contenant des images.
Si nous listons le contenu de ce dossier, nous aurons :
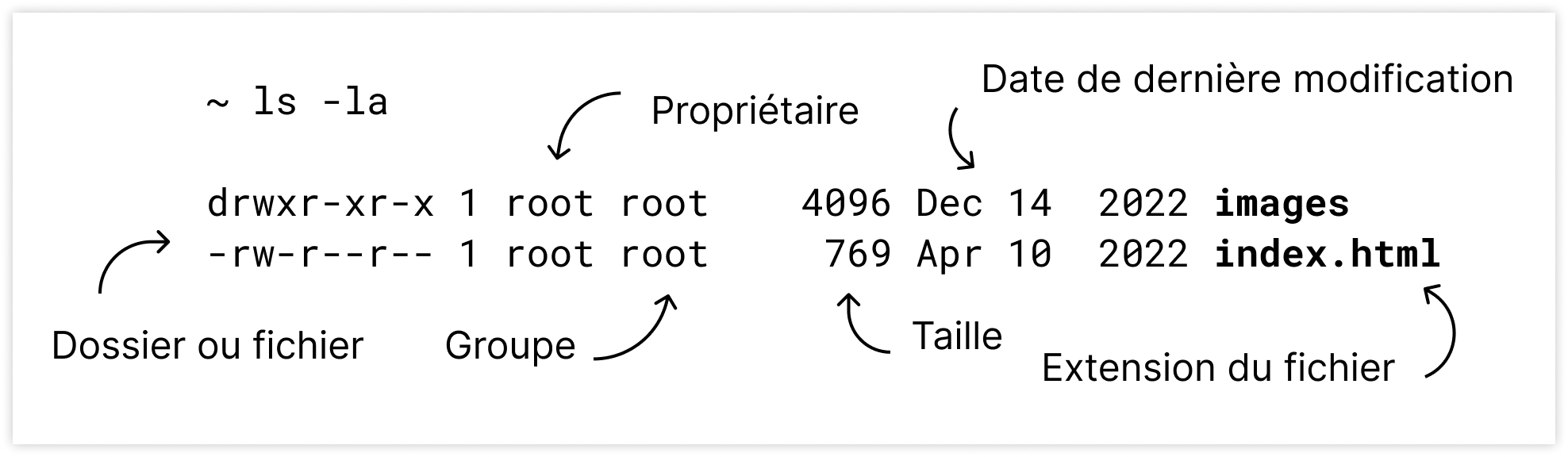
Décomposons ce retour :
- drwxr-xr-x : les permissions du dossier.
- Nous savons que c’est un dossier grâce à la première lettre (un « d »). Le fichier commence lui par « – » ce qui indique un fichier quelconque. Il n’y a qu’un troisième cas commun, un « l » dans le cas d’un lien symbolique.
- Il y a ensuite trois groupes distincts, les permissions pour l’utilisateur, le groupe, et les autres. W = write (écriture), R = read (lecture) et X = execute (exécution). Cet enchaînement de lettres indique donc concrètement qu’il s’agit d’un dossier sur lequel l’utilisateur a tous les droits, le groupe et les autres n’ont pas les droits d’écriture.
- 1 : il s’agit du nombre de liens.
- root root : qui est l’utilisateur de ce dossier, et quel est son groupe.
- 64 : taille en octet.
- 22 nov 17:03 : date et heure de la création du dossier.
- images : le nom.
Puisque les ordinateurs fonctionnent en binaire, les permissions sont parfois représentées par des chiffres et non des lettres. C’est notamment le cas pour la commande chmod qui permet de modifier les permissions.
Chaque permission a une représentation en valeur binaire et octale, ce qui donne par exemple :
- rw-r–r– : 110 100 100 (644)
- rwxr-xr-x : 111 101 101 (755)
Simuler un serveur Linux avec Docker
À la fin de cet article, vous trouverez des commandes basiques et utiles à lancer sur Linux. Pour éviter tout effet de bord ou si vous n’avez pas de machine Unix à proximité, il est possible de facilement mettre en place un serveur Linux avec Docker. Pour ce faire, il suffit de télécharger l’application : pour en savoir plus, ne pas hésiter à lire notre article sur Docker.
Une fois l’application lancée, entrer cette commande afin de créer un container Linux Debian :
docker run --name debian-sandbox -p 22:22 -p 8080:80 -it debian /bin/bash -lLes commandes à utiliser sous Linux
Une commande s’écrit et se lance depuis un interface de commande (CLI) qui permet de communiquer avec le système, comme le ferait une interface graphique (GUI) de façon moins abstraite. Le système va ensuite exécuter un programme répondant à cette commande.
Anatomie d’une commande
Concrètement, une commande est constituée uniquement de texte. À l’heure des moteurs de recherche et plus récemment des intelligences artificielles comme ChatGPT, nous nous attendons à ce qu’une machine puisse comprendre toute seule ce que nous voulons dire. Mais c’est tout l’inverse pour une commande, ici il n’y a pas de place pour l’approximatif et tout doit être millimétré sous peine d’échouer :
- Le nom de la commande : généralement le nom du programme qui va être exécuté ou des suites de lettres qui font référence à des commandes natives
- Les paramètres : ils viennent ajouter des informations afin d’utiliser la commande plus finement. Ils sont souvent délimités par des
-ou--et peuvent être écrits dans le désordre. - Les fichiers : si une commande interagit avec des fichiers ou dossiers, ils seront écrits sans notion de paramètre et à la fin de la commande.

Faute d’orthographe, coquille… la commande ne sera pas lancée si elle n’est pas parfaitement écrite. Certaines commandes peuvent également devenir très dangereuses à un caractère près, comme le redoutable rm -rf ./ en oubliant le point. En effet, ce caractère indiquant le passage d’un chemin relatif à un chemin absolu, il désignera donc la commande de tout supprimer depuis la racine du serveur. Comme dit le dicton, don’t try this at ~ (home) !
Quelques commandes natives de Linux
Ces commandes peuvent être utilisées telles quelles, elles n’ont pas ou peu besoin de paramètres ni d’input particulier. Elles ont vocation à donner des informations ou à parcourir les sources.
Elles sont constituées de quelques lettres seulement et sont facilement mémorables grâce à l’action à laquelle elles font référence. Make directory pour la commande mkdir, ou encore list pour ls…
Parcourir les dossiers et fichiers
Afficher le répertoire actuel
pwdSe déplacer dans un dossier, le chemin indiqué peut être relatif ./dossier-suivant/ ou absolu /premier-dossier/dossier-suivant/
cd <nom-du-repertoire>Revenir au dossier précédent
cd ../Lister tous les fichiers et dossiers dans le dossier courant. Des paramètres permettent d’améliorer l’output :
- l : sous forme de liste
- h : lisible pour un humain, notamment poids
- a : fichiers cachés
ls -lhEffectuer une recherche dans des fichiers
grep pattern filesInformations de stockage sur tous les répertoires du serveur
df -hCréer et déplacer des dossiers et fichiers
Créer un répertoire
mkdir <nom-du-repertoire>Créer un fichier
touch fichier.txtChanger le propriétaire du fichier
chown <user>:<groupe> <nom-du-fichier>Changer les permissions du fichier
chmod 770 <nom-du-fichier>Créer une copie du fichier en premier paramètre selon le nom donné en deuxième paramètre
cp <fichier-a-copier.txt> <fichier-copié.txt>Déplacer ou renommer un fichier ou dossier
mv old.txt /chemin/Compresser un dossier et fichier. Souvent utilisé pour créer un backup, une sauvegarde des sources du site. Les paramètres précisent de compresser (c) en utilisant gzip (z) pour la compression, avec de la verbose (v) et en indiquant le nom du fichier créé (f). Les variables permettent d’indiquer la date courante dans le nom du fichier. Il peut ensuite être décompressé en remplaçant la compression par la décompression (x) :
tar -czvf backup-$(date +%Y-%m-%d_%H-%M).tar.gz .tar -xzvf backup-2023-01-01_00-00.tar.gzCommandes supplémentaires
Pour d’autres commandes, elles seront le fruit de logiciels à installer dans le serveur, probablement avec le gestionnaire de paquet APT (Advanced Packaging Tool) dans le cas d’une distribution Debian.
Transfert de fichiers avec Rsync
Permet de transférer des fichiers entre un serveur et une machine locale. C’est un outil puissant connu pour sa rapidité et sa commodité puisqu’il est capable de reprendre suite à une perte de connexion.
rsync -avz --rsh "ssh -p 22" <user>@<host>:/chemin/vers/le/fichier.txt .-avz: il s’agit en fait de trois options différentes, qui indiquent une archive (-a) effectuée de façon recursive et en conservant tous les liens, permissions… qui compresse à la volée (-z) et avec de la verbose (-v).--rsh "ssh -p 22": utiliser le protocole SSH via le port 22<user>@<host>: les éléments requis à la connexion SSH, le user suivi de l’hôte/chemin/vers/le/fichier.txt .: le chemin pour arriver jusqu’au fichier sur le serveur. Le point à la fin permet de récupérer le fichier à l’endroit où est lancée la commande en local.
Sauvegardes de données MySQL
Dans le cas d’une base de données MySQL ou MariaDB, il est possible de générer un dump, une sauvegarde la base de données au moment précis dans un fichier .sql dont le nom est renseigné en fin de commande.
mysqldump -u <username> -p<password> <dbname> > <fichier>.sqlCe fichier peut ensuite être importé avec la commande suivante :
mysql -u <username> -p<password> <dbname> < <fichier>.sqlCes quelques commandes sont à retenir absolument pour une utilisation régulière et vous permettront de naviguer facilement sur un serveur Linux ou dans tous systèmes d’exploitation Unix, comme un ordinateur sous MacOS par exemple.










